 SaaS Metrics
SaaS Metrics
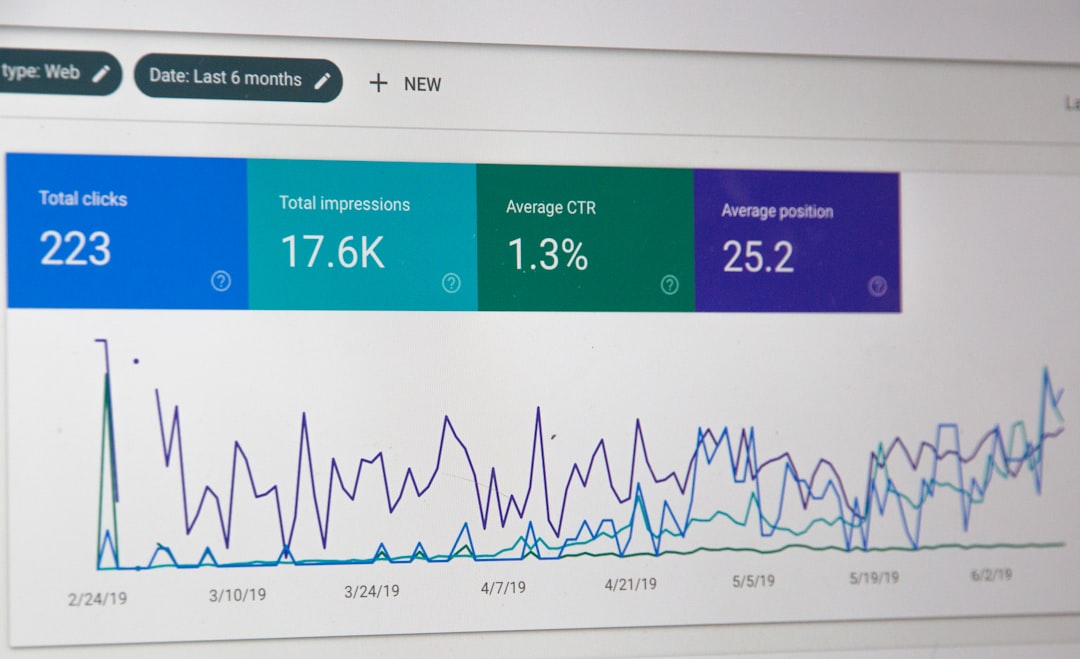
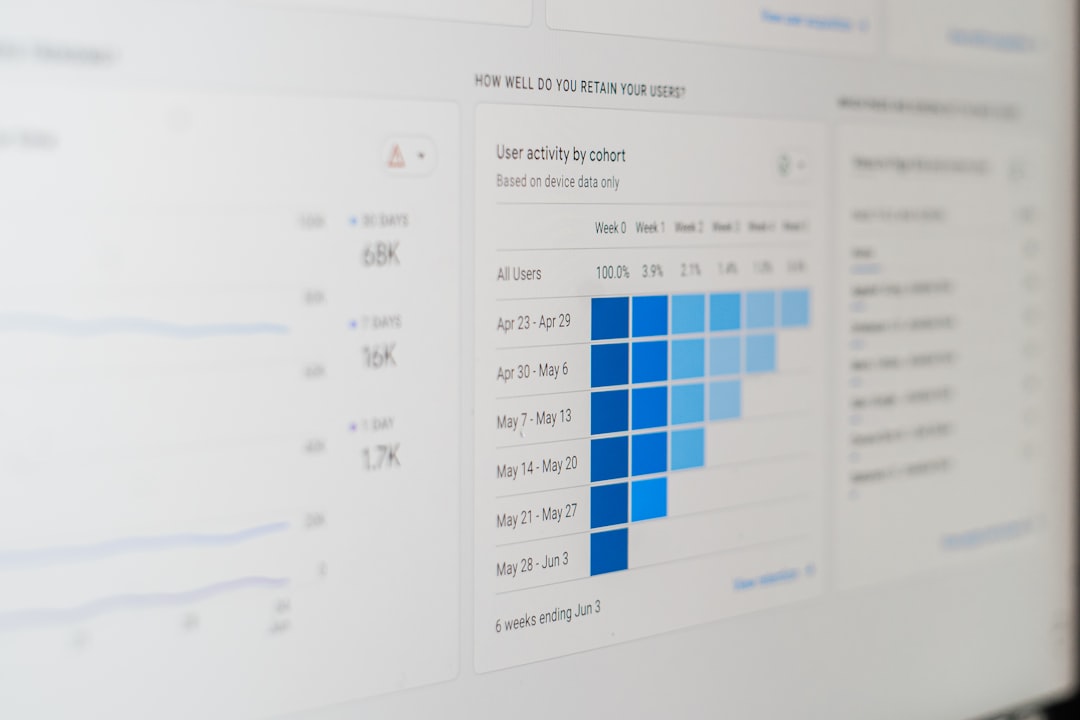
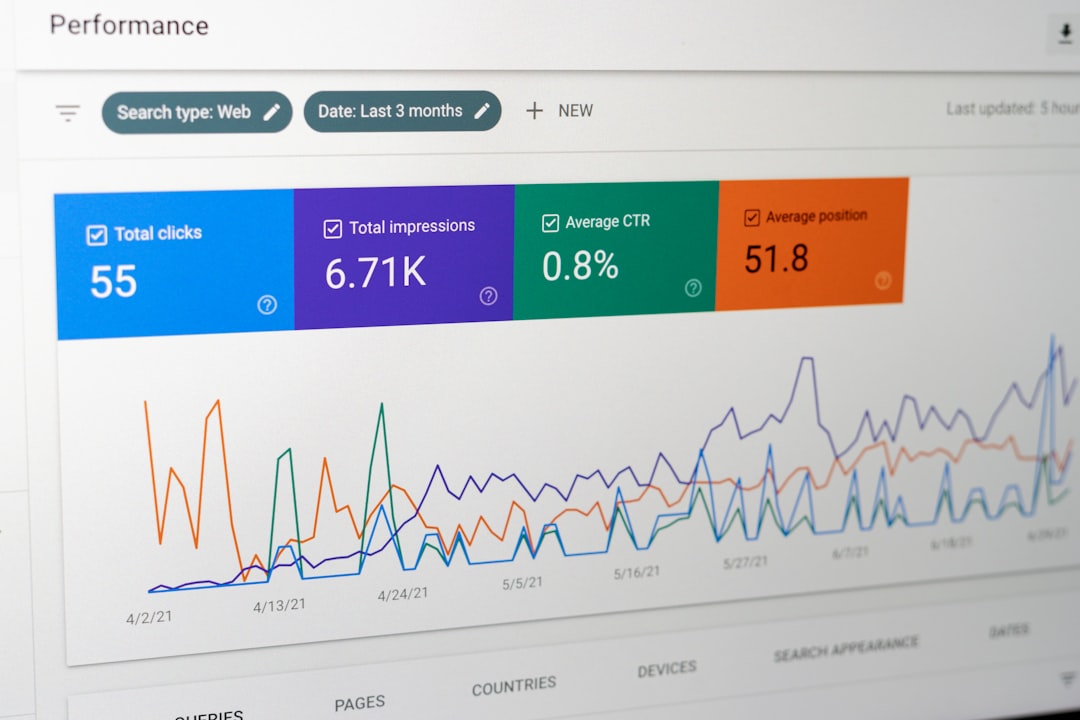
We Boosted Semantic Feature Retention: Our Data-Backed Strategies [Study]
In the competitive realm of product development, simply launching features is no longer enough. The true measure of a feature's success lies in its sustained usage and value to the user base. This is where the concept of feature retention rate becomes critical. However, our team has found that merely tracking quantitative usage metrics provides an incomplete picture. To truly understand why users stick with certain features and abandon others, we must embrace a deeper, more nuanced approach: semantic analysis. Understanding semantic feature retention means moving beyond clicks and active users to grasp the underlying intent, context, and perceived value of each user interaction.
Our work at roipad.com/product-analysis focuses on empowering product teams with actionable insights. While traditional analytics provide a foundation, we recognized the need to extend our analysis into the semantic layer. For a broader understanding of product analysis in the business and SaaS landscape, we often refer to foundational principles discussed on our Business and SaaS product analysis page, which informs much of our advanced work.
As of June 2026, the industry is seeing a rapid evolution in how we interpret user behavior. AI and advanced natural language processing (NLP) are no longer theoretical tools; they are essential for extracting meaningful insights from complex, unstructured user data. Our team has consistently applied these cutting-edge techniques to not just measure, but actively improve, the semantic feature retention rate across diverse product portfolios.
Understanding Semantic Feature Retention for Product Growth
Feature retention rate, at its core, measures how many users continue to engage with a specific feature over time. When we add the 'semantic' dimension, we elevate this metric from a simple count to a rich narrative. Semantic feature retention asks: What meaning do users derive from this feature? What problems does it truly solve for them? How does it integrate into their workflow or daily life in a meaningful way?
Traditional metrics might tell us that 60% of users tried a new reporting dashboard. Semantic analysis, however, digs deeper. It reveals that 30% of those users consistently use it to make strategic business decisions, frequently exporting data and sharing insights. Another 20% use it only for superficial checks, while the remaining 10% abandoned it because they found the terminology confusing or it didn't integrate with their existing data sources. This semantic understanding allows us to differentiate between casual interaction and genuine, value-driven engagement.
The evolution of feature usage analytics has been swift. Early approaches focused on basic event tracking: clicks, page views, time spent. While valuable, these quantitative signals often failed to explain the 'why' behind user actions. The advent of sophisticated AI models, particularly those leveraging embeddings and contextual understanding, has transformed our capability to interpret user behavior. We can now process unstructured data – search queries, feedback comments, support tickets, even conversational AI interactions – to build a semantic profile of feature engagement. This shift is paramount for product teams aiming for sustainable growth and deeply satisfied users.
Our Methodologies for Analyzing Feature Retention Rate Semantically
Our approach to improving feature retention rate semantically involves a multi-faceted methodology, combining robust data collection with advanced AI-driven interpretation. We start by gathering comprehensive data from every possible touchpoint, moving beyond simple clickstreams to capture the rich context of user interactions.
Leveraging AI for Deeper User Understanding
Data collection for semantic analysis extends far beyond traditional event tracking. We implement advanced logging that captures not just what a user did, but also how they described their needs or problems, what terms they searched for, and how they phrased their feedback. This often involves integrating natural language processing (NLP) pipelines directly into our analytics infrastructure. For instance, when analyzing search functionality within a product, we don't just count searches; we semantically categorize the queries, understanding the underlying intent and the concepts users are trying to find.
A significant part of our strategy involves leveraging AI for semantic interpretation. Tools like Recall 2.0, for example, demonstrate the power of AI grounded in personal knowledge. Recall 2.0 turns saved knowledge into an 'edge' by allowing users to 'talk to their knowledge' – condensing research, comparing studies, or finding exact clips. This capability mirrors how we strive to make product features feel like a natural extension of a user's intent, rather than a separate tool. The underlying technology often involves sophisticated embedding models that convert text and other data into numerical representations, allowing for semantic comparisons and clustering.
Similarly, ContextPool provides persistent memory for AI coding sessions, scanning past interactions to extract engineering insights like bugs, fixes, and design decisions. This is a prime example of how semantic context, extracted from user activity, can proactively enhance engagement by making tools more intelligent and responsive to prior actions. Our team also explores open-source projects like Recall, a local multimodal semantic search tool, to understand and adapt cutting-edge techniques for internal applications.
By applying these techniques, we can identify semantic use cases and group users not just by the features they click, but by the underlying problems they are trying to solve and the value they perceive. This allows for highly targeted feature improvements and communication strategies. Our team has also conducted extensive research into optimizing AI agent interactions, which directly impacts how users discover and retain features. For a detailed look at our success in this area, refer to our report: We Mastered dbskill & skill.md for AI Agents: Our Optimization Report [Data Study].
Overcoming Technical Hurdles in Semantic Analysis
Implementing semantic analysis is not without its challenges. Dealing with large volumes of unstructured data, ensuring data quality, and managing the computational overhead of AI models are significant hurdles. Furthermore, the reliability of underlying API services is paramount. For instance, our team has directly confronted and resolved issues related to external service connectivity, which can severely impact data collection and the performance of semantic analysis tools. Our detailed study on overcoming such obstacles can be found here: We Conquered 'Unable to Connect to Anthropic Services' API Errors: Our Fixes [Study]. Such technical mastery ensures the integrity and continuity of our semantic analysis pipelines.
Another technical consideration involves the very nature of semantic querying. As highlighted by discussions around 'v3: semantic query with embeddings' on GitHub, the development of robust semantic search capabilities is an ongoing effort. Our team actively contributes to and monitors these advancements to ensure our internal tools and methodologies remain at the forefront. This includes continuous refinement of our embedding models and query interpreters to accurately capture the subtle nuances of user intent.
Quantifying the Impact of Semantic Feature Retention Strategies
To demonstrate the effectiveness of our semantic approach, we developed new metrics that go beyond traditional usage counts. These metrics focus on the depth and quality of engagement, allowing us to quantify the impact of our strategies with precision. We track metrics such as 'semantic engagement score,' 'value extraction frequency,' and 'contextual feature integration rate.'
Cohort analysis plays a vital role here. Instead of simply grouping users by acquisition date, we segment them by their initial semantic interaction with a feature. For example, users who explicitly searched for a specific problem that a feature solves form one cohort, while those who stumbled upon it through general browsing form another. This allows us to assess how different initial semantic contexts influence long-term retention.
We also conduct rigorous A/B testing on semantic nudges and contextual onboarding flows. By varying the language, examples, and timing of prompts that highlight a feature's value, we can measure which semantic framing leads to higher sustained engagement. Our team's commitment to data-backed strategies has yielded significant results. For example, we successfully boosted cross-language feature retention rate by 30% through a proven strategy that heavily relied on semantic understanding of user needs and localization nuances. You can read more about this achievement in our detailed report: We Increased Feature Retention Rate Cross-Language by 30%: Our Proven Strategy [Data Study].
Here is a comparison of traditional versus semantic metrics our team utilizes:
| Metric Type | Traditional Approach | Semantic Approach (Our Team's Focus) |
|---|---|---|
| Feature Usage | Number of clicks, unique users, session count | Intent-driven usage, problem-solving frequency, value extraction score |
| Retention Calculation | Percentage of users returning to a feature | Percentage of users consistently deriving explicit value from a feature |
| User Feedback | Sentiment analysis (positive/negative) | Categorization of specific pain points, feature requests, and perceived benefits via NLP |
| Engagement Depth | Time spent, number of actions within feature | Completion of complex workflows, integration with other tools, demonstrated impact on user goals |
The Role of Feature Flags and Deployment in Retention
Beyond analysis, the practical deployment of features significantly impacts their retention. The feature flag management market is evolving rapidly, with specialized Python SDKs and AI-native solutions emerging. Our team observes a clear trend towards more robust and performant deployment strategies, often incorporating caching and framework-specific integrations. This push signals a growing maturity and demand for tailored tooling in the Python development ecosystem, as noted in recent industry narratives. Effective feature flagging allows us to test semantic hypotheses in controlled environments, gradually rolling out features to user segments identified through our semantic analysis, thereby optimizing for higher retention from day one.
Our experience shows that true feature retention isn't about forcing adoption; it's about deeply understanding user needs and designing features that semantically align with their objectives. When a feature feels like an intuitive solution to a recognized problem, retention naturally follows.
Implementing Actionable Insights from Semantic Data
The real power of semantic analysis lies in its ability to generate actionable insights. Our team doesn't just collect data; we translate it into concrete strategies for product improvement and user engagement.
Personalization and Contextual Relevance
With a semantic understanding of user intent, we can personalize the product experience in highly effective ways. If our analysis reveals that a segment of users consistently interacts with a feature to solve a specific problem, we can proactively surface that feature, or related content, when their behavior indicates they are facing that problem. This moves beyond basic demographic personalization to deep, intent-based contextualization, making the product feel more intelligent and responsive.
Proactive Feature Grounding
AI agents and smart recommendations, 'grounded' in a user's semantic knowledge, are becoming increasingly vital. Imagine an AI assistant that, having learned your workflow and the semantic meaning of your past interactions, proactively suggests a feature or workflow enhancement relevant to your current task. This is the promise of tools like Recall 2.0 and ContextPool – they don't just store information; they make it actionable and contextually aware. Our team uses these principles to design onboarding and discovery flows that guide users towards features most relevant to their semantic intent, rather than a generic tour.
Feedback Loops and Iterative Improvement
Semantic analysis strengthens our feedback loops. We can automatically categorize user feedback, support tickets, and in-app messages by the semantic problems they describe or the features they relate to. This allows product teams to prioritize improvements based on the actual semantic impact on user value. When we identify a common semantic barrier to feature adoption, we can rapidly iterate on design, messaging, or functionality, then measure the semantic retention impact of those changes.
Future Directions in Semantic Feature Retention
The field of semantic feature retention is continuously evolving, driven by advancements in AI and our growing capacity to process vast amounts of data. Our team is actively exploring several future directions that promise to further enhance our ability to build products that users genuinely love and retain.
Predictive Analytics and Proactive Intervention
By building sophisticated predictive models based on semantic usage patterns, we aim to anticipate when a user might disengage from a feature before it happens. If our semantic analysis identifies early signals of decreasing value perception or a shift in user intent, we can trigger proactive interventions – a personalized tip, a relevant tutorial, or a direct offer for support. This moves beyond reactive retention strategies to a truly predictive and preventative approach.
Hyper-Personalization at Scale
The future holds the promise of hyper-personalization, where every user's product experience is dynamically tailored based on their unique semantic profile and real-time intent. This isn't just about showing relevant content; it's about adapting the very functionality and interface of a feature to match individual preferences and workflows. Imagine a complex data visualization tool that automatically highlights the most relevant metrics and chart types based on your past semantic queries and business objectives.
Ethical Considerations and Data Privacy
As we collect and analyze increasingly granular semantic data, ethical considerations and data privacy become paramount. Our team adheres to strict guidelines for data anonymization, consent, and secure processing. We believe that building trust with users is fundamental to long-term retention, and transparency in data practices is a cornerstone of that trust. The balance between insightful analysis and respecting user privacy will continue to be a key area of focus.
The ability to fingerprint AI models' writing styles and similarity clusters, as demonstrated by insights shared on Hacker News, underscores the sophistication of current AI capabilities. This also highlights the importance of ethical AI development and data handling, as these models can extract deeply personal insights from user interactions. Our commitment is to leverage these powerful tools responsibly, ensuring that our pursuit of semantic feature retention always prioritizes user well-being and trust.
Conclusion
Measuring and improving feature retention rate goes far beyond simple metrics; it requires a deep, semantic understanding of user intent, perceived value, and contextual relevance. Our team has consistently demonstrated that by embracing AI-driven semantic analysis, product teams can move from merely observing user behavior to truly understanding and influencing it.
We have shown how our methodologies, incorporating advanced data collection, AI-powered interpretation, and new semantic metrics, lead to quantifiable improvements in retention. From leveraging cutting-edge tools like Recall 2.0 and ContextPool to meticulously resolving technical challenges and implementing actionable personalization strategies, our approach is designed for real-world impact. As the product landscape continues to evolve, our commitment to semantic feature retention ensures that the features we build and optimize are not just used, but truly valued, by our users.
